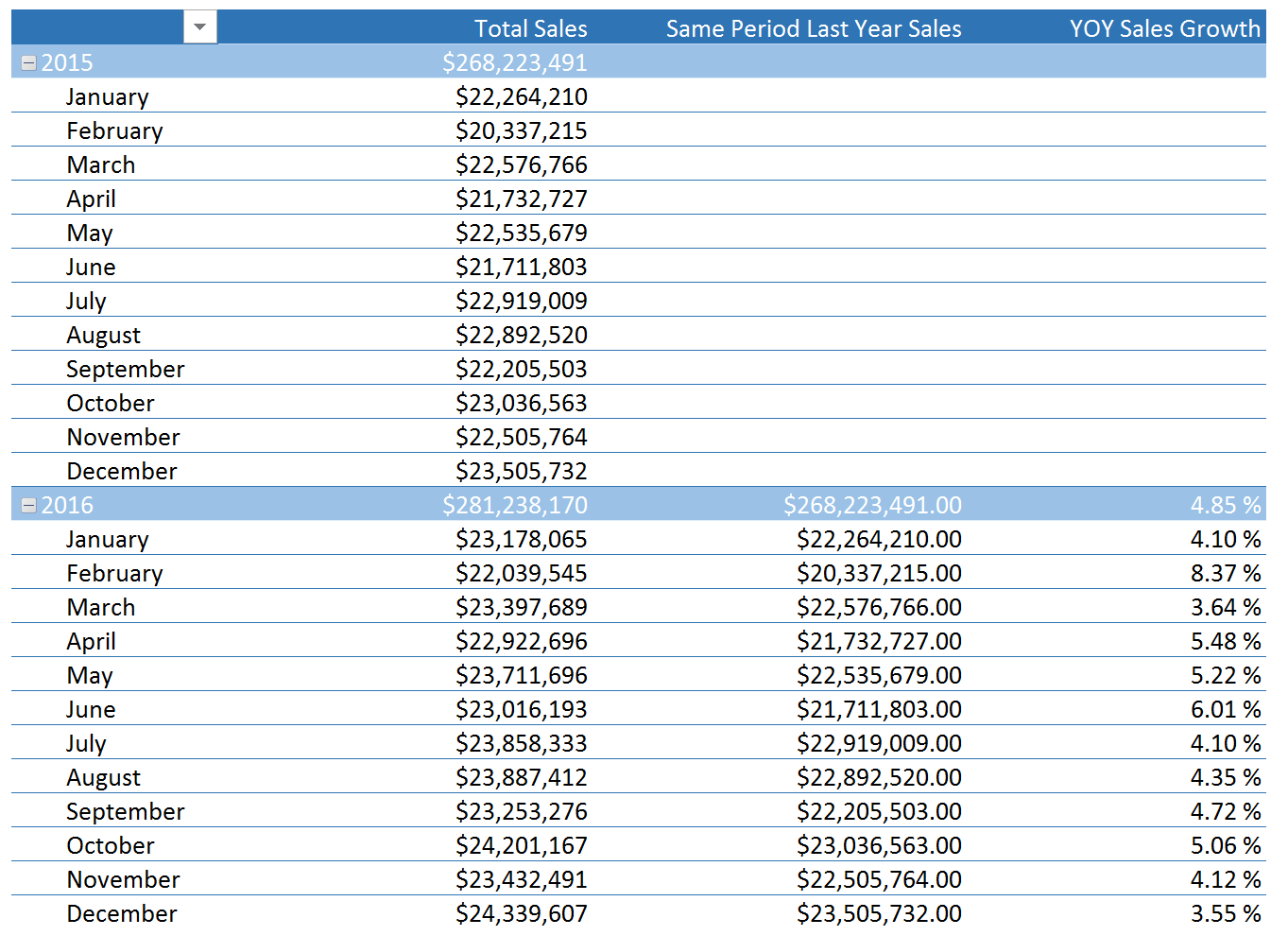
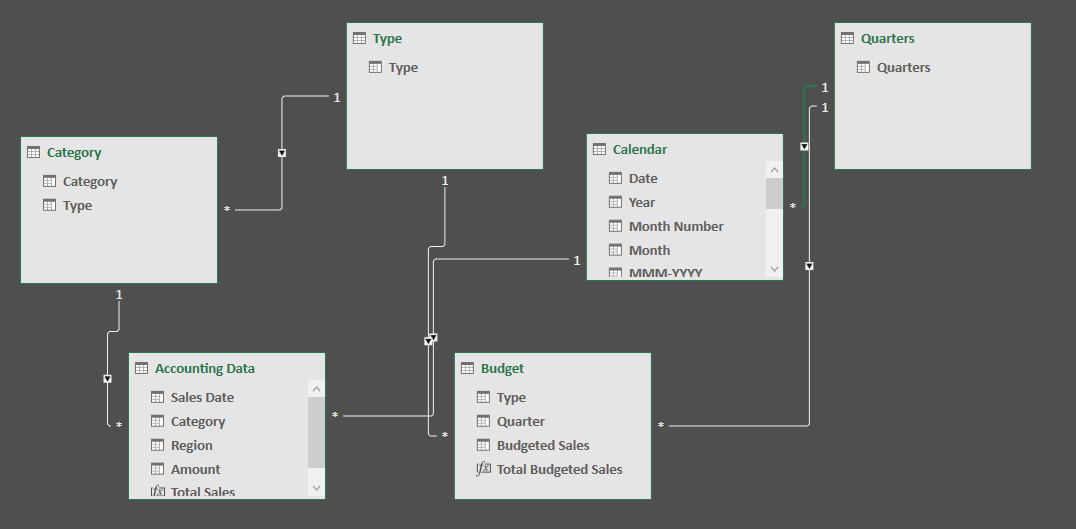
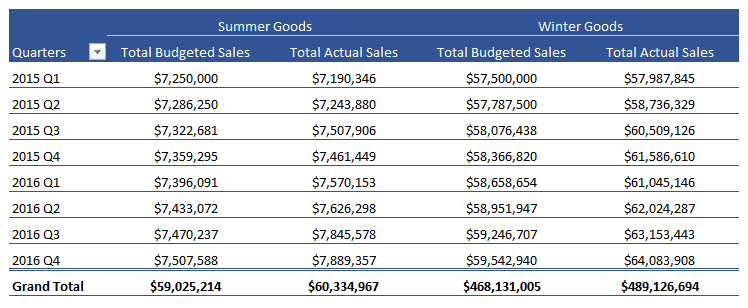
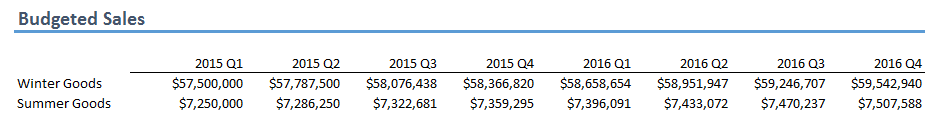Uma das principais fontes de dados hoje são as redes sociais. Permita-me demonstrar um exemplo da vida real: lidar, analisar e extrair informações de dados de redes sociais em tempo real usando uma das soluções eco de Big Data mais importantes, Apache Spark e Python.

Neste artigo, vou ensinar-lhe como criar um aplicativo simples que lê fluxos online do Twitter usando o Python e, em seguida, processa os tweets usando o Apache Spark Streaming para identificar hashtags e, finalmente, retorna as principais hashtags de tendências e representa esses dados em um painel de controle.
Criando suas próprias credenciais para as APIs do Twitter
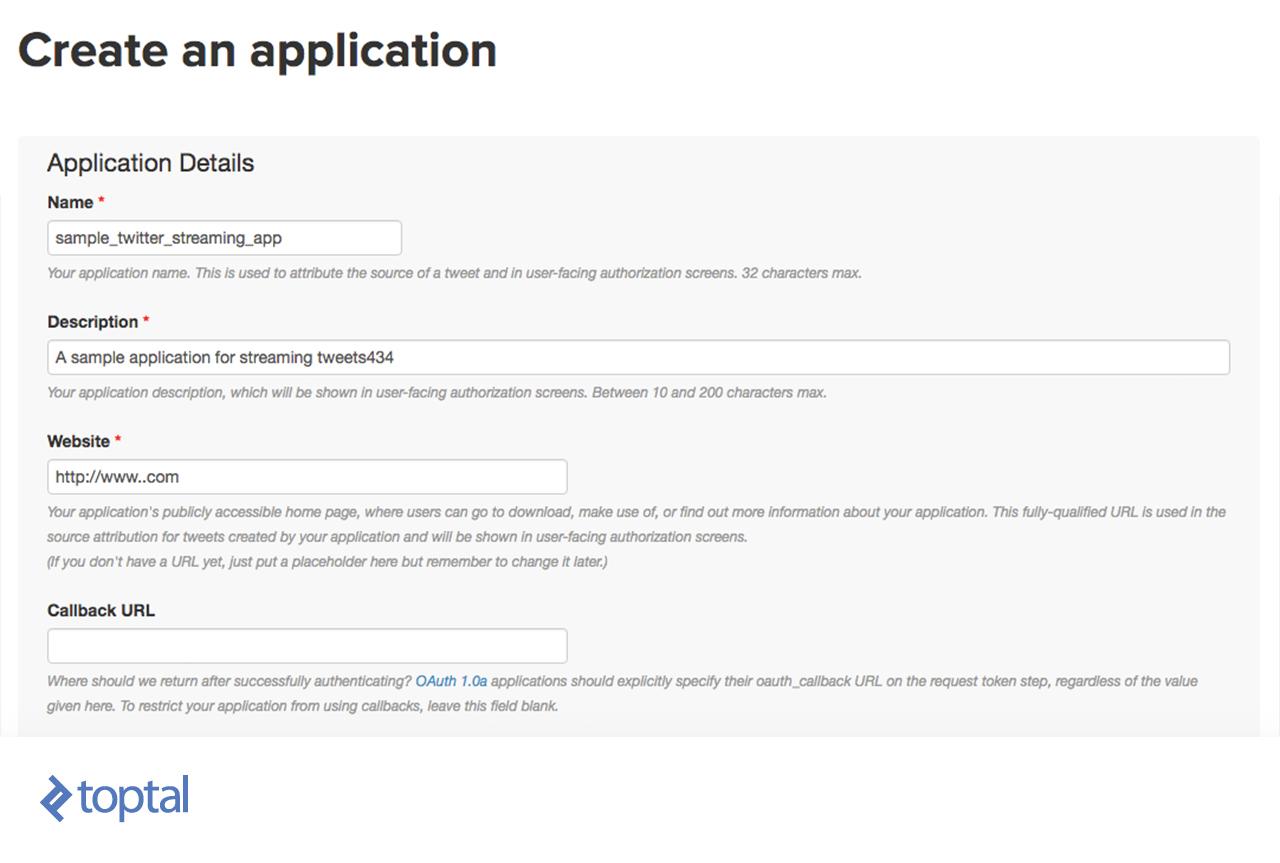
Para obter tweets do Twitter, você precisa se registrar no TwitterApps clicando em "Criar novo aplicativo" e, em seguida, preencha o formulário abaixo, depois clique em "Criar seu aplicativo do Twitter".
Em segundo lugar, acesse seu aplicativo recém-criado e abra a guia "Keys and Access Tokens". Em seguida, clique em "Gerar meu token de acesso".
Seus novos tokens de acesso aparecerão abaixo.
E agora você está pronto para o próximo passo.
Criando o Twitter HTTP Client
Nesta etapa, vou mostrar-lhe como criar um cliente simples que obterá os tweets da API do Twitter usando o Python e os passará para a instância Spark Streaming. Vai ser fácil de seguir para qualquer Python Developer.
Primeiro, vamos criar um arquivo chamado [twitter_app.py] e, em seguida, adicionaremos o código juntos como abaixo.
Importe as bibliotecas que usaremos abaixo:
import socket
import sys
import requests
import requests_oauthlib
import json
E adicione as variáveis que serão usadas no OAuth para se conectar ao Twitter conforme abaixo:
# Replace the values below with yours
ACCESS_TOKEN = 'YOUR_ACCESS_TOKEN'
ACCESS_SECRET = 'YOUR_ACCESS_SECRET'
CONSUMER_KEY = 'YOUR_CONSUMER_KEY'
CONSUMER_SECRET = 'YOUR_CONSUMER_SECRET'
my_auth = requests_oauthlib.OAuth1(CONSUMER_KEY, CONSUMER_SECRET,ACCESS_TOKEN, ACCESS_SECRET)
Agora, vamos criar uma nova função chamada get_tweets que chamará o URL da API do Twitter e retornará a resposta para um fluxo de tweets.
def get_tweets(): url = 'https://stream.twitter.com/1.1/statuses/filter.json' query_data = [('language', 'en'), ('locations', '-130,-20,100,50'),('track','#')] query_url = url + '?' + '&'.join([str(t[0]) + '=' + str(t[1]) for t in query_data]) response = requests.get(query_url, auth=my_auth, stream=True) print(query_url, response) return response
Em seguida, crie uma função que obtenha a resposta acima e extraia o texto dos tweets do objeto JSON de todos os tweets. Depois disso, envie todos os tweets à instância Spark Streaming (serão discutidos mais tarde) através de uma conexão TCP.
def send_tweets_to_spark(http_resp, tcp_connection): for line in http_resp.iter_lines(): try: full_tweet = json.loads(line) tweet_text = full_tweet['text'] print("Tweet Text: " + tweet_text) print ("------------------------------------------") tcp_connection.send(tweet_text + '\n') except: e = sys.exc_info()[0] print("Error: %s" % e)
Agora vamos fazer a parte principal, um app host de conexão socket, na qual o Spark vai se conectar. Vamos configurar o IP aqui para ser o localhost, pois todos serão executados na mesma máquina e na porta 9009. Então chamaremos o método get_tweets, que fizemos acima, para obter os tweets do Twitter e passar sua resposta junto com a conexão de socket para send_tweets_to_spark para enviar os tweets para Spark.
TCP_IP = "localhost" TCP_PORT = 9009 conn = None s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.bind((TCP_IP, TCP_PORT)) s.listen(1) print("Waiting for TCP connection...") conn, addr = s.accept() print("Connected... Starting getting tweets.") resp = get_tweets() send_tweets_to_spark(resp, conn)
Configurando nossa aplicação de streaming de Apache Spark
Vamos construir o nosso aplicativo Spark streaming que fará o processamento em tempo real para os tweets recebidos, extrairá os hashtags deles e calculará quantas hashtags foram mencionadas.

Primeiro, temos que criar uma instância de Contexto Spark (sc), então criamos o Contexto de Transmissão ssc de sc com um intervalo de lote de dois segundos que fará a transformação em todos os fluxos recebidos a cada dois segundos. Observe que estabelecemos o nível de log para ERROR para desabilitar a maioria dos logs que o Spark escreve.
Nós definimos um ponto de controle aqui para permitir a verificação periódica do RDD; Isso é obrigatório para ser usado em nosso aplicativo, pois usaremos transformações com estado (serão discutidas mais adiante na mesma seção).
Em seguida, definimos nosso DStream dataStream principal que se conectará ao servidor de socket que criamos antes, na porta 9009, e leia os tweets dessa porta. Cada registro no DStream será um tweet.
from pyspark import SparkConf,SparkContext from pyspark.streaming import StreamingContext from pyspark.sql import Row,SQLContext import sys import requests # create spark configuration conf = SparkConf() conf.setAppName("TwitterStreamApp") # create spark context with the above configuration sc = SparkContext(conf=conf) sc.setLogLevel("ERROR") # create the Streaming Context from the above spark context with interval size 2 seconds ssc = StreamingContext(sc, 2) # setting a checkpoint to allow RDD recovery ssc.checkpoint("checkpoint_TwitterApp") # read data from port 9009 dataStream = ssc.socketTextStream("localhost",9009)
Agora, vamos definir a nossa lógica de transformação. Primeiro vamos dividir todos os tweets em palavras e colocá-los em palavras RDD. Então, vamos filtrar apenas hashtags de todas as palavras e mapeá-los para um par de (hashtag, 1) e colocá-los no hashtags RDD.
Então precisamos calcular quantas vezes a hashtag foi mencionada. Nós podemos fazer isso usando a função reductionByKey. Esta função calculará quantas vezes a hashtag foi mencionada por cada lote, ou seja, irá redefinir as contagens em cada lote.
No nosso caso, precisamos calcular as contagens em todos os lotes, então usaremos outra função chamada updateStateByKey, pois esta função permite que você mantenha o estado de RDD ao atualizá-lo com novos dados. Desta forma, é chamado de Transformação de Estado.
Note que, para usar updateStateByKey, você precisa configurar um ponto de controle e o que fizemos na etapa anterior.
# split each tweet into words words = dataStream.flatMap(lambda line: line.split(" ")) # filter the words to get only hashtags, then map each hashtag to be a pair of (hashtag,1) hashtags = words.filter(lambda w: '#' in w).map(lambda x: (x, 1)) # adding the count of each hashtag to its last count tags_totals = hashtags.updateStateByKey(aggregate_tags_count) # do processing for each RDD generated in each interval tags_totals.foreachRDD(process_rdd) # start the streaming computation ssc.start() # wait for the streaming to finish ssc.awaitTermination()
O updateStateByKey assume uma função como um parâmetro chamado de função de atualização. Ele é executado em cada item no RDD e faz a lógica desejada.
No nosso caso, criamos uma função de atualização chamada aggregate_tags_count que somará todos os novos valores para cada hashtag e os adiciona ao total_sum que é a soma em todos os lotes, e salva os dados em tags_totals RDD.
def aggregate_tags_count(new_values, total_sum): return sum(new_values) + (total_sum or 0)
Em seguida, fazemos o processamento em tags_totals RDD em cada lote para convertê-lo em tabela temporária usando o Spark SQL Context e, em seguida, execute uma instrução de seleção para recuperar os dez principais hashtags com suas contagens e colocá-los em frame de dados hashtag_counts_df.
def get_sql_context_instance(spark_context): if ('sqlContextSingletonInstance' not in globals()): globals()['sqlContextSingletonInstance'] = SQLContext(spark_context) return globals()['sqlContextSingletonInstance'] def process_rdd(time, rdd): print("----------- %s -----------" % str(time)) try: # Get spark sql singleton context from the current context sql_context = get_sql_context_instance(rdd.context) # convert the RDD to Row RDD row_rdd = rdd.map(lambda w: Row(hashtag=w[0], hashtag_count=w[1])) # create a DF from the Row RDD hashtags_df = sql_context.createDataFrame(row_rdd) # Register the dataframe as table hashtags_df.registerTempTable("hashtags") # get the top 10 hashtags from the table using SQL and print them hashtag_counts_df = sql_context.sql("select hashtag, hashtag_count from hashtags order by hashtag_count desc limit 10") hashtag_counts_df.show() # call this method to prepare top 10 hashtags DF and send them send_df_to_dashboard(hashtag_counts_df) except: e = sys.exc_info()[0] print("Error: %s" % e)
O último passo no nosso aplicativo Spark é enviar o quadro de dados hashtag_counts_df para o aplicativo do painel. Então, vamos converter o quadro de dados em dois arrays, um para os hashtags e outro para suas contagens. Em seguida, nós os enviaremos para o aplicativo do painel de controle através da API REST.
def send_df_to_dashboard(df): # extract the hashtags from dataframe and convert them into array top_tags = [str(t.hashtag) for t in df.select("hashtag").collect()] # extract the counts from dataframe and convert them into array tags_count = [p.hashtag_count for p in df.select("hashtag_count").collect()] # initialize and send the data through REST API url = 'http://localhost:5001/updateData' request_data = {'label': str(top_tags), 'data': str(tags_count)} response = requests.post(url, data=request_data)
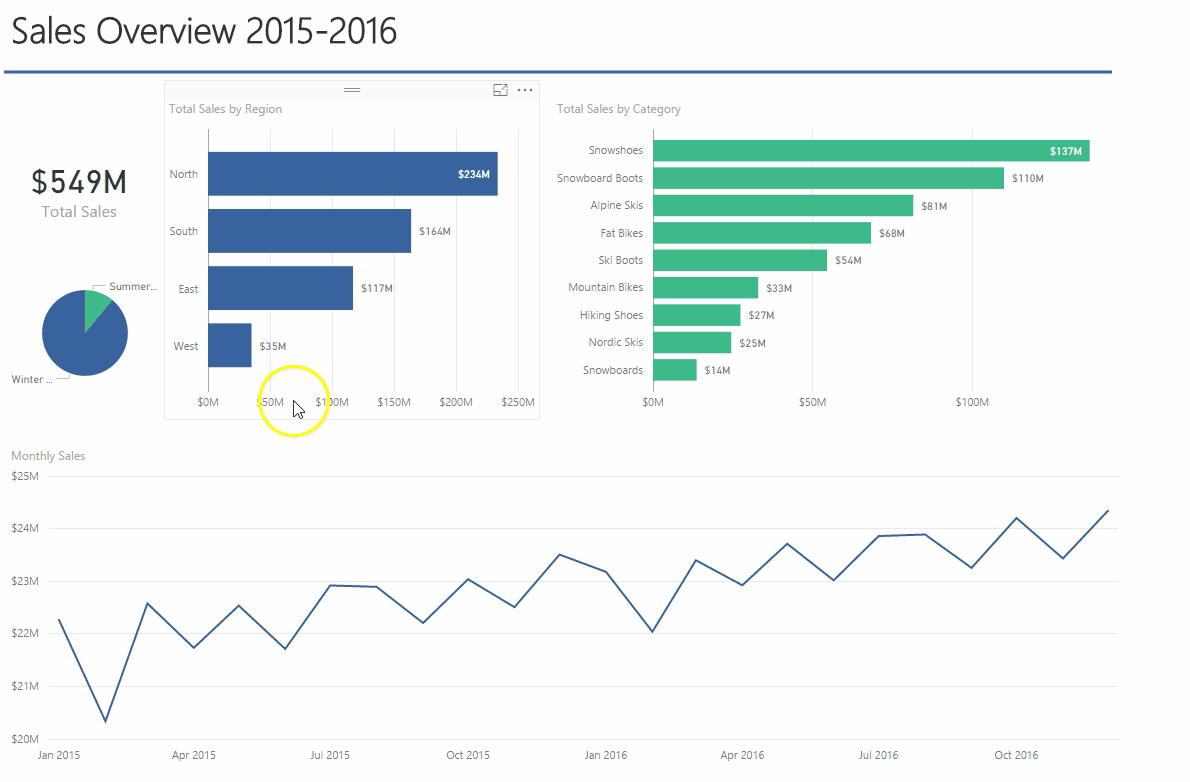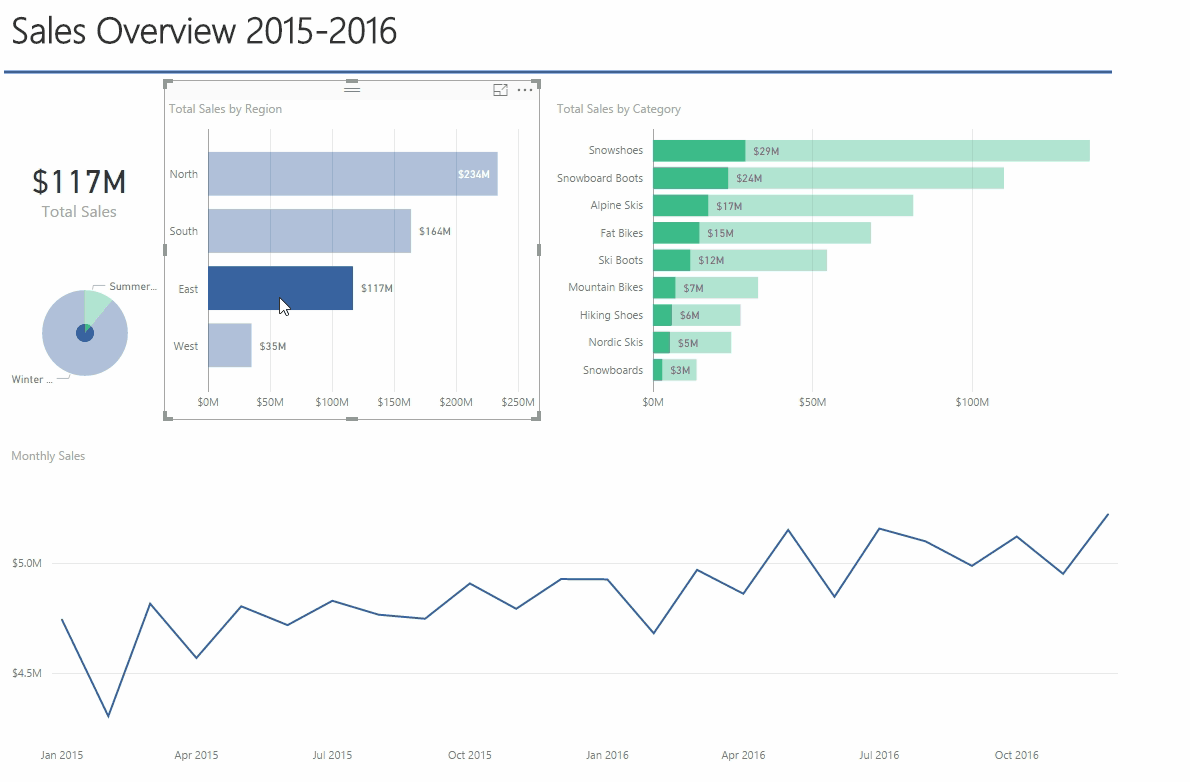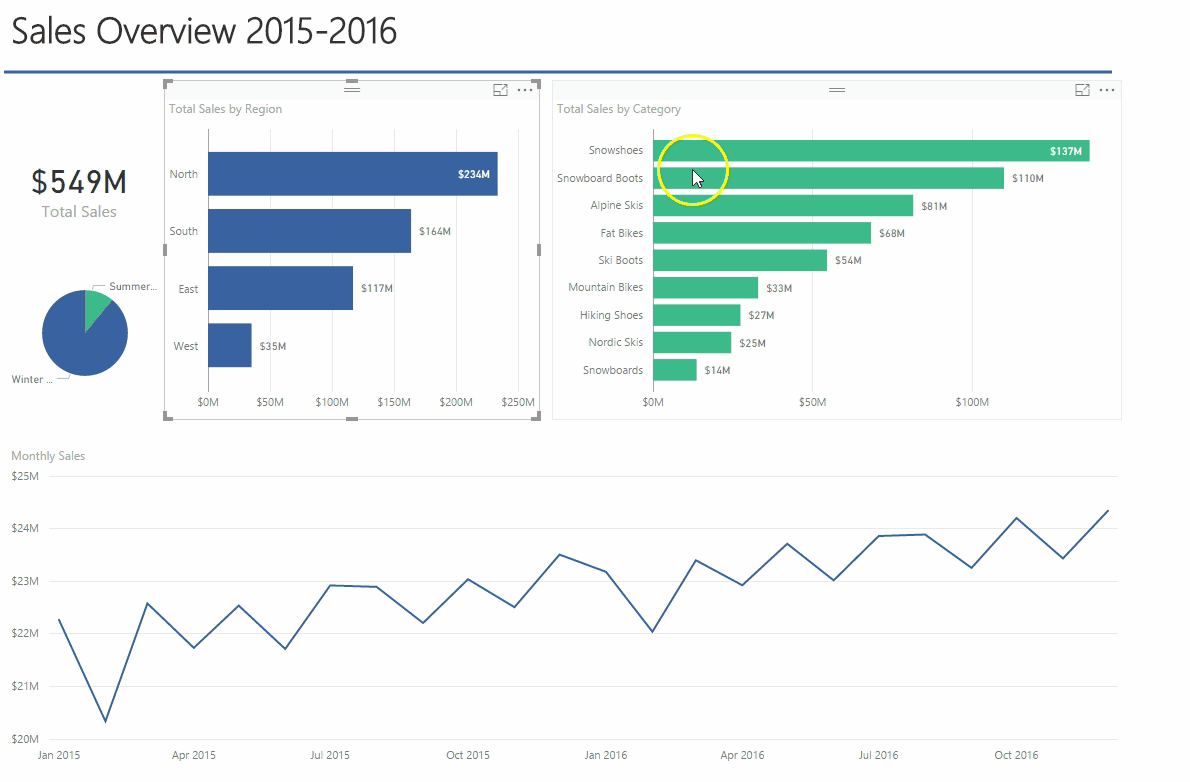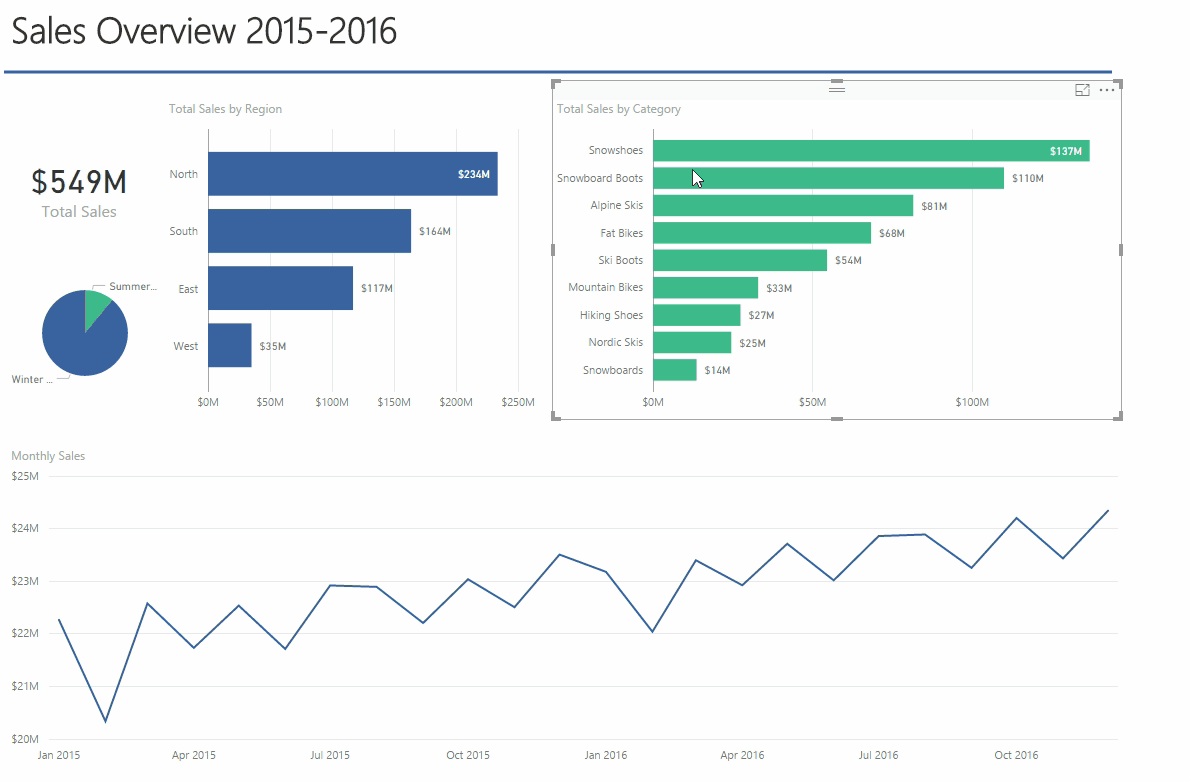
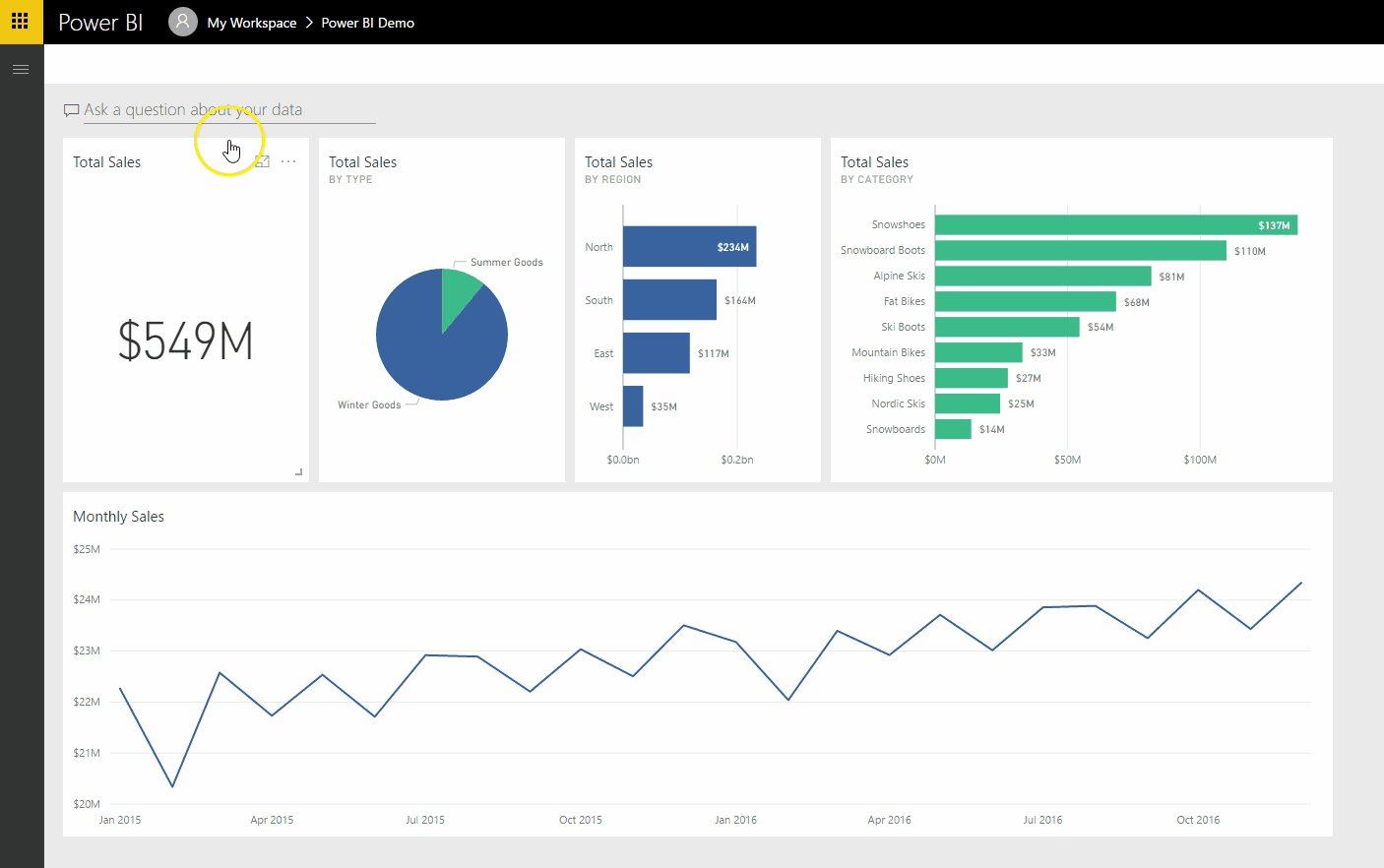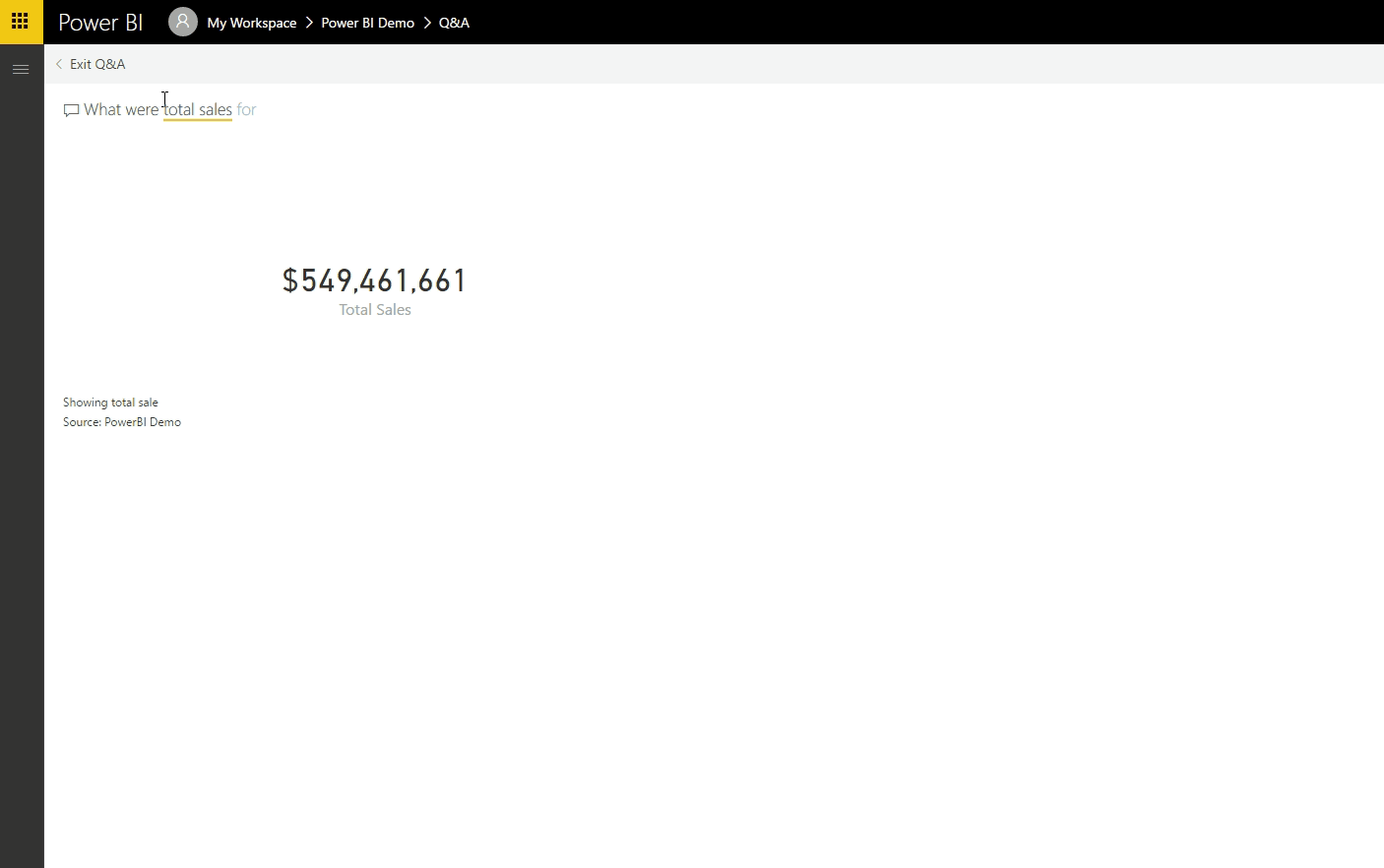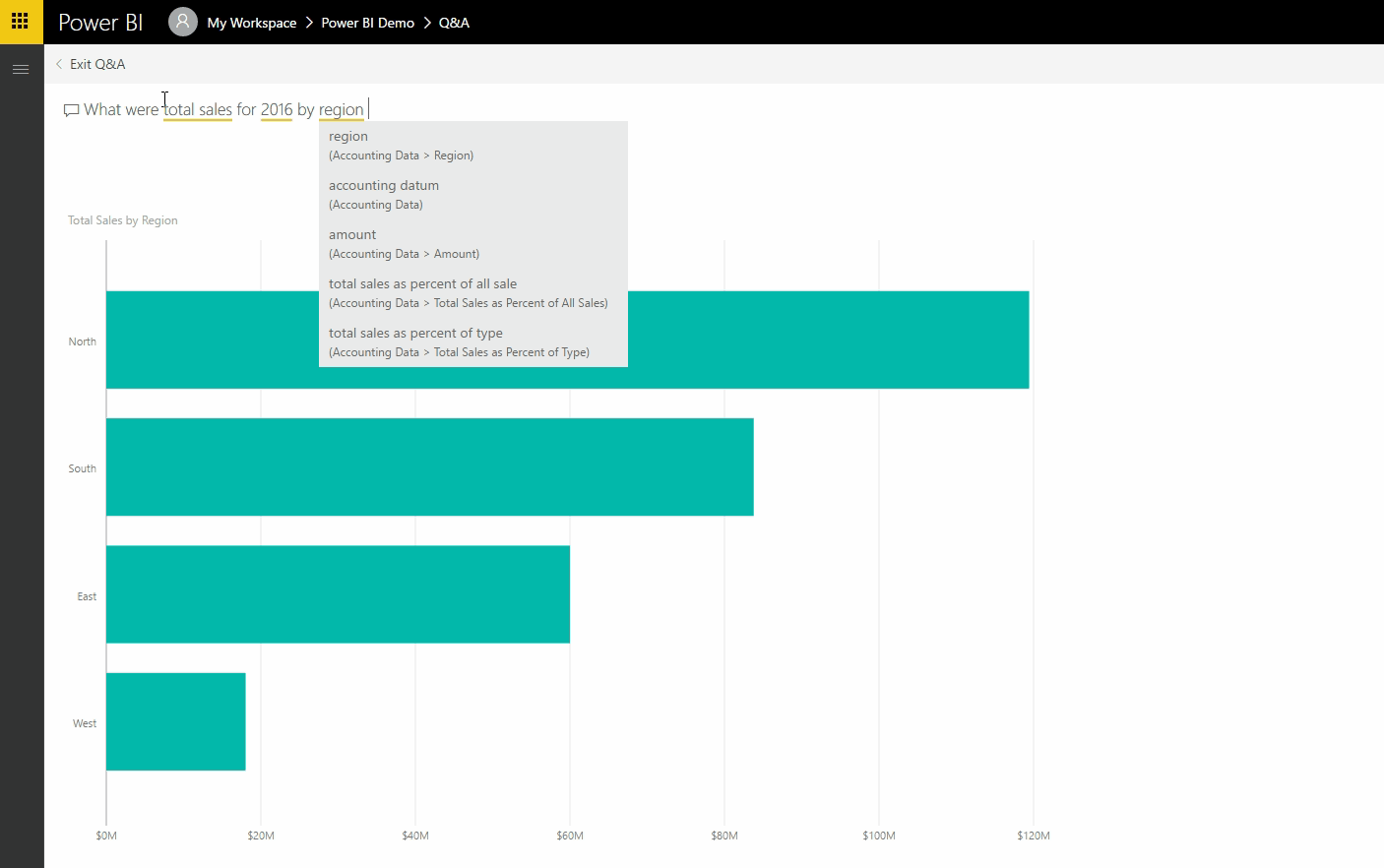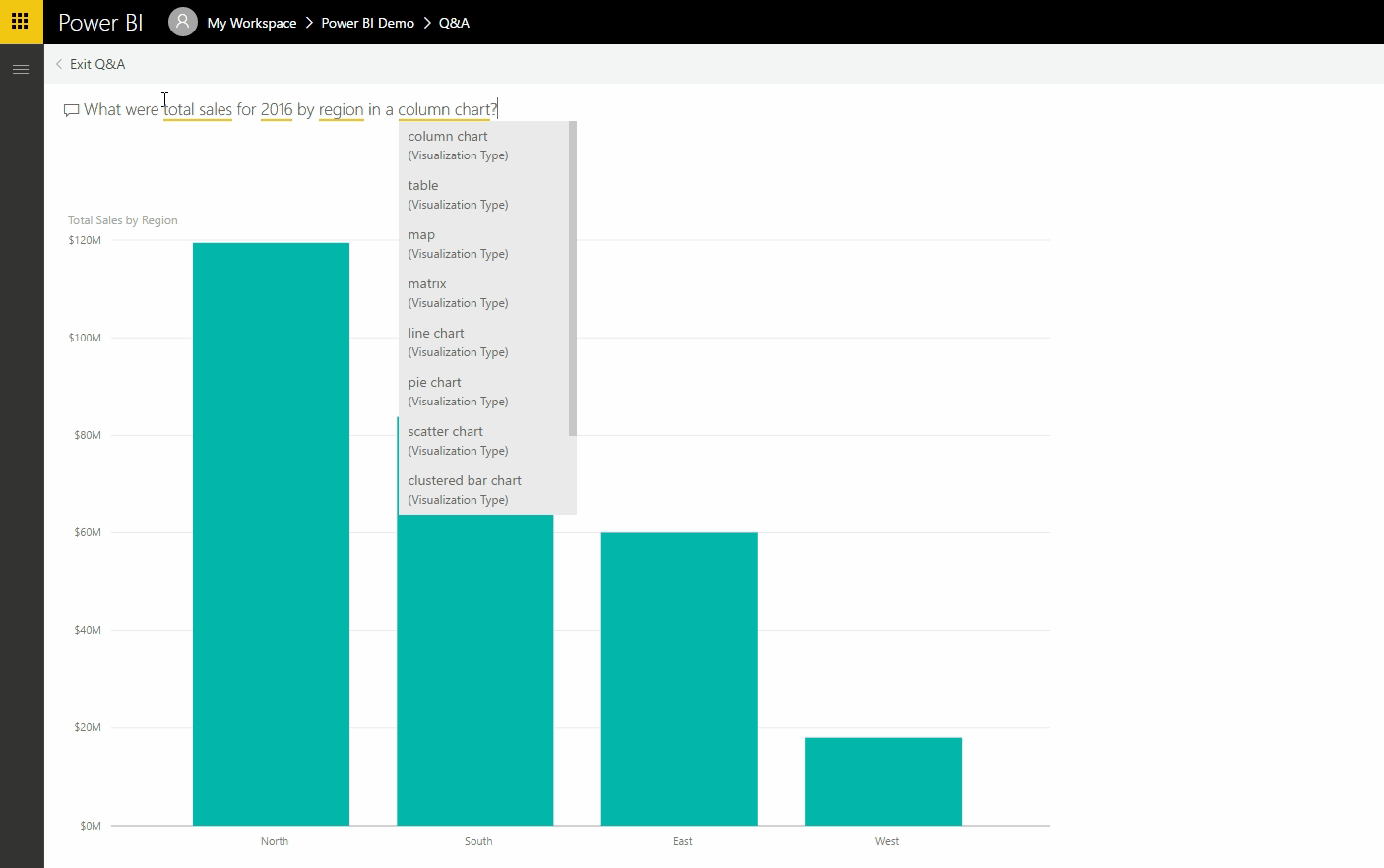
Finalmente, aqui está um exemplo de saída do Spark Streaming durante a execução e a impressão do hashtag_counts_df, você notará que a saída é impressa exatamente a cada dois segundos, de acordo com os intervalos do lote.

Crie um painel de controle em tempo real simples para representar os dados
Agora, vamos criar um aplicativo de painel simples que será atualizado em tempo real pela Spark. Vamos construí-lo usando Python, Flask e Charts.js.
Primeiro, vamos criar um projeto Python com a estrutura abaixo e baixar e adicionar o arquivo Chart.js no diretório estático.
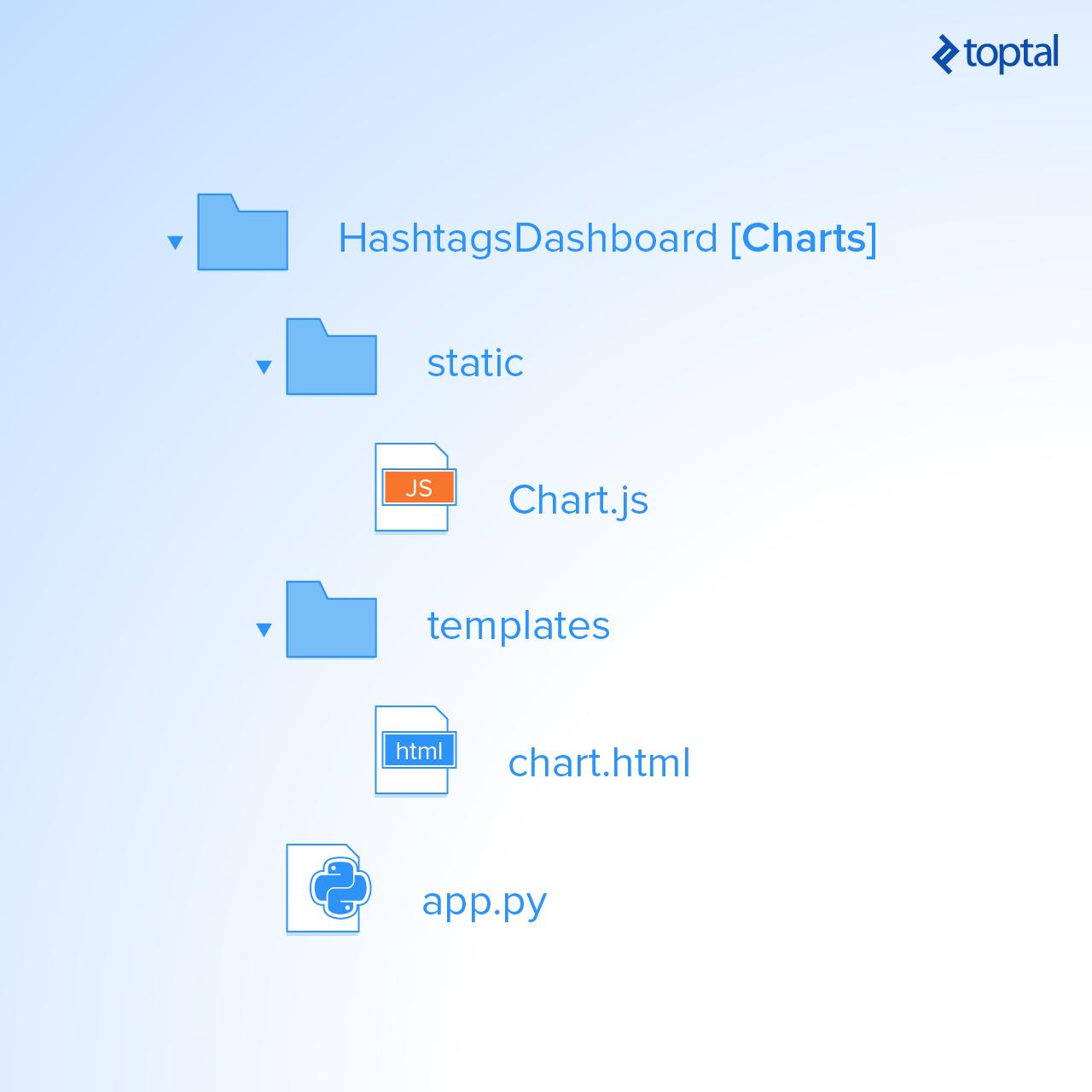
Então, no arquivo da aplicação.py, criamos uma função chamada update_data, que será chamada pelo Spark através da URL http://localhost:5001/ updateData para atualizar as matrizes de valores e etiquetas globais.
Além disso, a função refresh_graph_data é criada para ser chamada pela solicitação AJAX para retornar os novos rótulos e matrizes de valores atualizados como JSON. A função get_chart_page renderizará a página chart.html quando chamada.
from flask import Flask,jsonify,request from flask import render_template import ast app = Flask(__name__) labels = [] values = [] @app.route("/") def get_chart_page(): global labels,values labels = [] values = [] return render_template('chart.html', values=values, labels=labels) @app.route('/refreshData') def refresh_graph_data(): global labels, values print("labels now: " + str(labels)) print("data now: " + str(values)) return jsonify(sLabel=labels, sData=values) @app.route('/updateData', methods=['POST']) def update_data(): global labels, values if not request.form or 'data' not in request.form: return "error",400 labels = ast.literal_eval(request.form['label']) values = ast.literal_eval(request.form['data']) print("labels received: " + str(labels)) print("data received: " + str(values)) return "success",201 if __name__ == "__main__": app.run(host='localhost', port=5001)
Agora, vamos criar um gráfico simples no arquivo chart.html para exibir os dados da hashtag e atualizá-los em tempo real. Conforme definido abaixo, precisamos importar as bibliotecas de JavaScript Chart.js e jquery.min.js.
Na etiqueta do corpo, temos que criar uma tela e dar-lhe uma ID para fazer referência a ela ao exibir o gráfico usando o JavaScript na próxima etapa.
<!DOCTYPE html> <html> <head> <meta charset="utf-8"/> <title>Top Trending Twitter Hashtags</title> <script src='static/Chart.js'></script> <script src="//ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script> </head> <body> <h2>Top Trending Twitter Hashtags</h2> <div style="width:700px;height=500px"> <canvas id="chart"></canvas> </div> </body> </html>
Agora, vamos construir o gráfico usando o código JavaScript abaixo. Primeiro, obtemos o elemento de tela, e então criamos um novo objeto de gráfico e passamos o elemento de tela para ele e definimos seu objeto de dados como abaixo.
Observe que os labels de dados e os dados são delimitados com rótulos e variáveis de valores que são retornados enquanto renderiza a página ao chamar a função get_chart_page no arquivo app.py.
A última parte restante é a função que está configurada para fazer uma solicitação Ajax a cada segundo e chama a URL /refreshData, que executará refresh_graph_data em app.py e retornará os novos dados atualizados e, em seguida, atualizará o gráfico que renderiza os novos dados.
<script> var ctx = document.getElementById("chart"); var myChart = new Chart(ctx, { type: 'horizontalBar', data: { labels: [{% for item in labels %} "{{item}}", {% endfor %}], datasets: [{ label: '# of Mentions', data: [{% for item in values %} {{item}}, {% endfor %}], backgroundColor: [ 'rgba(255, 99, 132, 0.2)', 'rgba(54, 162, 235, 0.2)', 'rgba(255, 206, 86, 0.2)', 'rgba(75, 192, 192, 0.2)', 'rgba(153, 102, 255, 0.2)', 'rgba(255, 159, 64, 0.2)', 'rgba(255, 99, 132, 0.2)', 'rgba(54, 162, 235, 0.2)', 'rgba(255, 206, 86, 0.2)', 'rgba(75, 192, 192, 0.2)', 'rgba(153, 102, 255, 0.2)' ], borderColor: [ 'rgba(255,99,132,1)', 'rgba(54, 162, 235, 1)', 'rgba(255, 206, 86, 1)', 'rgba(75, 192, 192, 1)', 'rgba(153, 102, 255, 1)', 'rgba(255, 159, 64, 1)', 'rgba(255,99,132,1)', 'rgba(54, 162, 235, 1)', 'rgba(255, 206, 86, 1)', 'rgba(75, 192, 192, 1)', 'rgba(153, 102, 255, 1)' ], borderWidth: 1 }] }, options: { scales: { yAxes: [{ ticks: { beginAtZero:true } }] } } }); var src_Labels = []; var src_Data = []; setInterval(function(){ $.getJSON('/refreshData', { }, function(data) { src_Labels = data.sLabel; src_Data = data.sData; }); myChart.data.labels = src_Labels; myChart.data.datasets[0].data = src_Data; myChart.update(); },1000); </script>
Execução das aplicações em conjunto
Vamos executar os três aplicativos na ordem abaixo:
1. Cliente do aplicativo do Twitter.
2. Spark App.
3. Dashboard Web App.
Então você pode acessar o painel de controle em tempo real usando a URL
Agora, você pode ver seu gráfico sendo atualizado, conforme abaixo:
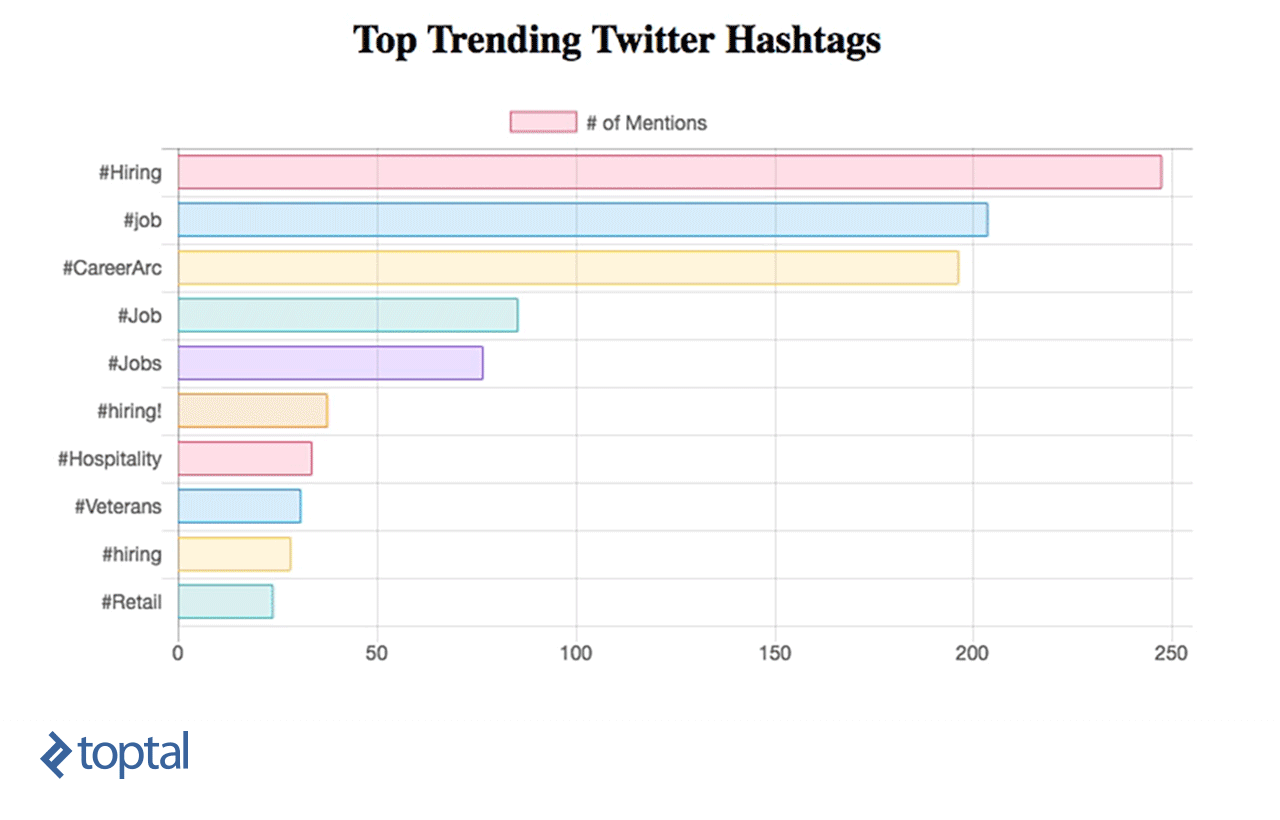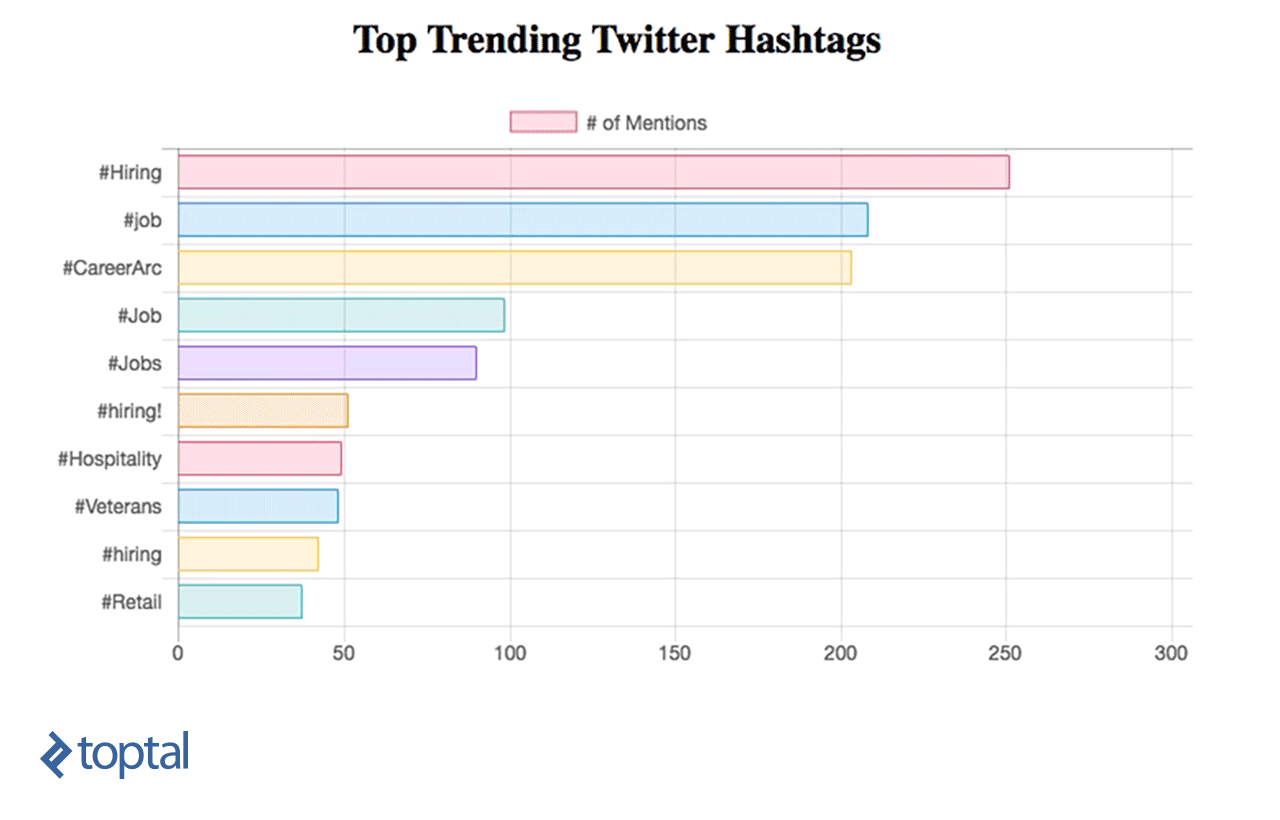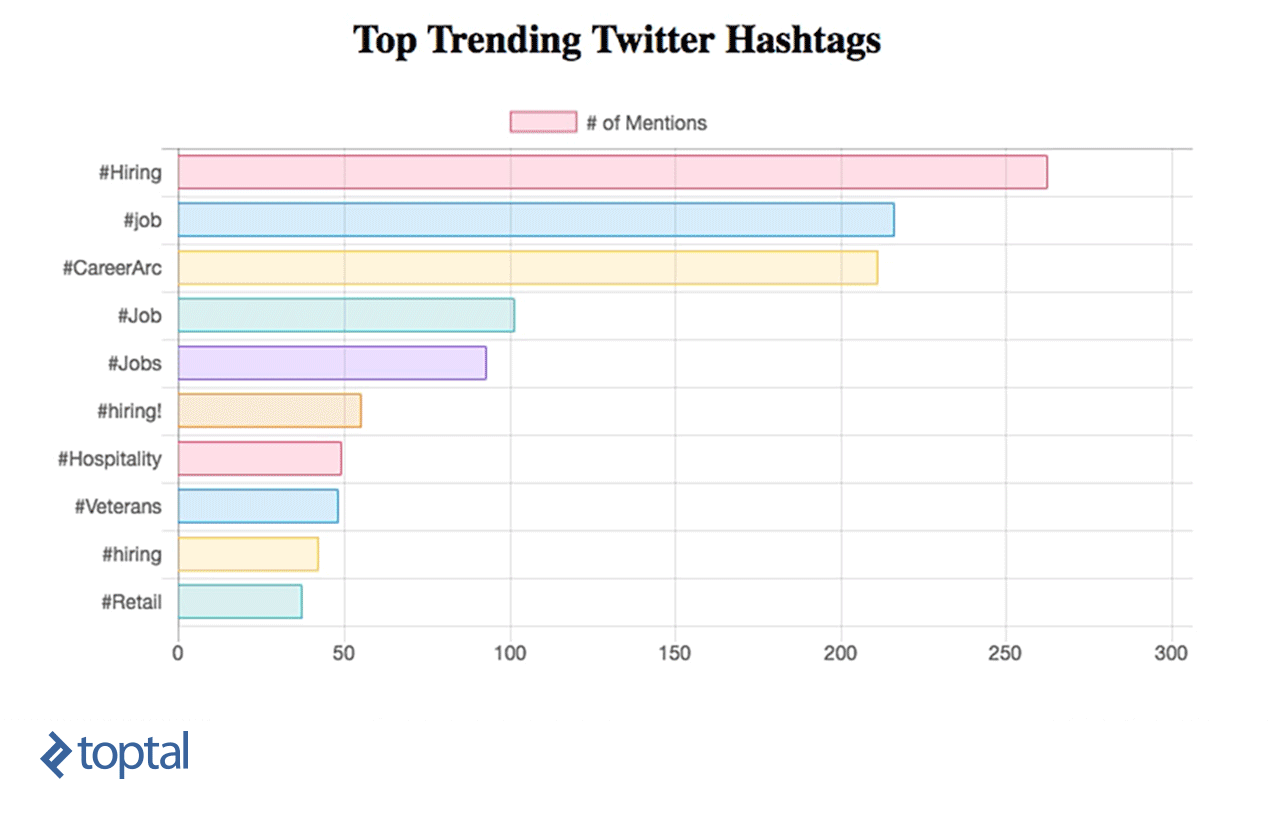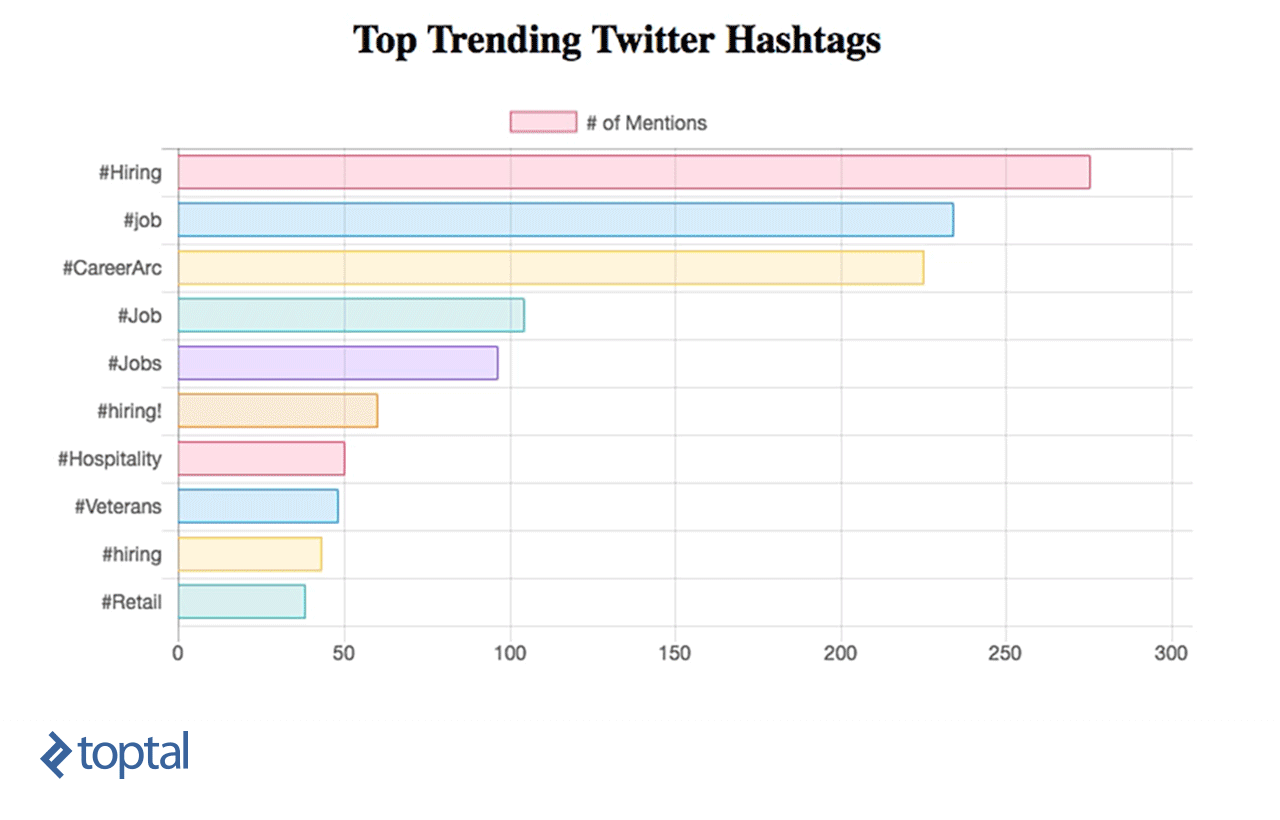
Apache Streaming - Casos de uso da vida real
Aprendemos a fazer análises de dados simples em dados em tempo real usando Spark Streaming e integrando-o diretamente com um painel simples usando um serviço web RESTful. A partir deste exemplo, podemos ver o quão poderoso é o Spark, pois captura um fluxo maciço de dados, transforma-o e extrai informações valiosas que podem ser usadas facilmente para tomar decisões a qualquer momento. Existem muitos casos de uso úteis que podem ser implementados e que podem servir para diferentes indústrias, como notícias ou marketing.

Exemplo da indústria de notícias
Podemos rastrear as hashtags mais freqüentemente mencionadas para saber quais os temas em que as pessoas estão falando mais nas mídias sociais. Além disso, podemos acompanhar hashtags específicos e seus tweets para saber o que as pessoas estão dizendo sobre tópicos ou eventos específicos no mundo.
Exemplo de Marketing
Podemos coletar o fluxo de tweets e, fazendo análises de sentimentos, classificamo-los e determinemos os interesses das pessoas, a fim de direcioná-los com ofertas relacionadas aos seus interesses.
Além disso, há muitos casos de uso que podem ser aplicados especificamente para grandes análises de dados e podem servir muitas indústrias. Para mais casos de uso de Apache Spark em geral, sugiro que você verifique uma de nossas postagens anteriores.
Eu encorajo você a ler mais sobre Spark Streaming a partir daqui para saber mais sobre suas capacidades e fazer uma transformação mais avançada nos dados para obter mais informações em tempo real.
BY HANEE' MEDHAT - FREELANCE SOFTWARE ENGINEER @TOPTAL